GPT-4o Benchmark - Detailed Comparison with Claude & Gemini

You've heard the hype about GPT-4o, the highly anticipated new AI model from OpenAI that promises to be a game-changer. But how does it actually stack up against other leading language models like Claude 3 and Gemini Pro?
In this article we will use comprehensive benchmark data that rigorously evaluated GPT-4o's performance against Claude and Gemini across a wide range of quantitative metrics and qualitative use cases.
You can finally go beyond the hype to make a data-driven assessment of GPT-4o's strengths, weaknesses, and unique differentiators.
Quantitative Comparisons
To rigorously evaluate GPT-4o against Claude and Gemini, researchers conducted a series of standardized benchmarks across a wide range of tasks and metrics. The benchmarking process followed established best practices to ensure fair and consistent evaluation.
Benchmarking Overview
The benchmarks covered a diverse range of tasks including:
Multi-Model Language Understanding (MMLU): Evaluates general language understanding across multiple tasks like coreference resolution, word sense disambiguation, and natural language inference. Higher scores are better.
General-Purpose Question Answering (GPQA): Tests question answering abilities on open-domain queries. Higher scores are better.
Mathematics (MATH): Assesses capabilities in solving math word problems. Higher scores are better.
Code Generation (HumanEval): Evaluates the models' ability to generate correct code from problem descriptions. Higher scores indicate better coding abilities.
Multi-Choice Generative Summarization (MGSM): Measures summarization capabilities by testing generation of concise summaries from longer text. Higher scores mean better summarization performance.
Complex Question Answering (DROP): Evaluates question answering abilities that require reasoning over long contexts. Models are scored on F1, with higher being better.
Key metrics evaluated were accuracy, F1 score, and task-specific metrics like perplexity and pass rates. In general, higher scores indicate better performance.
Benchmark Results
Model | MMLU (Undergraduate level knowledge) | GPQA (Graduate level reasoning) | MATH (Math Problem-solving) | HumanEval (Code) | MGSM (Multilingual Math) | DROP (Reasoning over text) |
|---|---|---|---|---|---|---|
GPT-4o | 88.7 | 53.6 | 76.6 | 90.2 | 90.5 | 83.4 |
GPT-4 | 86.5 | 49.1 | 72.2 | 87.6 | 88.6 | 85.4 |
GPT-3.5 | 70.0 | 28.1 | 34.1 | 48.1 | N/A | 64.1 |
Claude-3-Opus | 86.8 | 50.4 | 60.1 | 84.9 | 90.7 | 83.1 |
Claude-3-Sonnet | 79.0 | 40.4 | 43.1 | 73.0 | 83.5 | 78.9 |
Claude-3-Haiku | 75.2 | 33.3 | 38.9 | 75.9 | 75.1 | 78.4 |
Gemini-Ultra-1.0 | 83.7 | N/A | 53.2 | 74.4 | 79.0 | 82.4 |
Gemini-Pro-1.5 | 81.9 | N/A | 58.5 | 71.9 | 88.7 | 78.9 |
Llama3 (8b) | 68.4 | 34.2 | 30.0 | 62.2 | N/A | 58.4 |
Llama3 (70b) | 80.2 | 41.3 | 52.8 | 70.1 | 82.6 | 81.4 |
This single table provides an overview of how the models performed across the diverse set of benchmarking tasks.
GPT-4o demonstrated elite-level performance, achieving scores above 85 on multiple benchmarks like MMLU, HumanEval, and MGSM.
However, no single model dominated across every task. Claude and Gemini models showed strengths in certain areas as well.
Crowdsourced Evaluation
While the standardized benchmarks provide objective quantitative comparisons, it's also valuable to look at crowdsourced evaluations that incorporate real-world human judgments. The LMSYS Chatbot Arena is one such platform that has collected over 1,000,000 human pairwise comparisons to rank language models.
The LMSYS leaderboard uses these crowdsourced human evaluations to rank models on an Elo-scale, providing a qualitative view into their relative capabilities. The ranking factors in overall performance as well as strengths in areas like coding and handling longer queries.
Overall Ranking
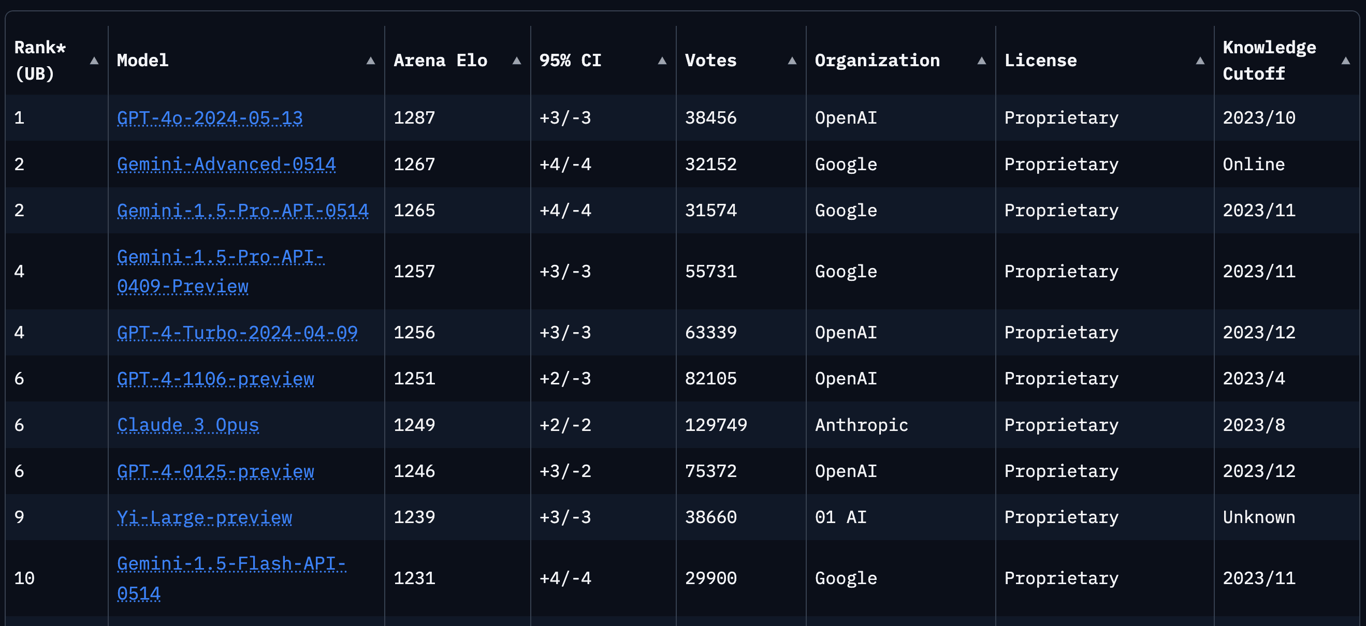
(Source, retrieved 17 Jun)
The overall LMSYS ranking has GPT-4o in the top spot, followed by the Gemini models from Google and GPT-4 variants from OpenAI. Claude-3-Opus from Anthropic also makes an appearance in the top tier.
Average Win Rate Against All Other Models
One key output from the LMSYS data is the average win rate for each model when compared against all other models in pairwise tests, assuming uniform sampling and no ties.
This chart visualizes those average win rates:
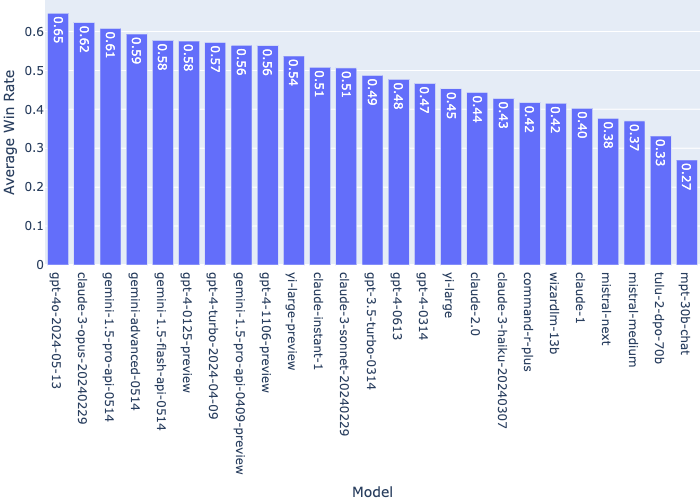
(Source, retrieved 17 Jun)
While GPT-4o topped the charts with a 65% average win rate, Claude-3-Opus and the Gemini models also showed strong performance based on these crowdsourced evaluations.
The LMSYS data provides a valuable real-world complement to the standardized benchmarks. With both quantitative and qualitative perspectives, we can develop a comprehensive understanding of the relative capabilities of GPT-4o versus other leading language models.
Qualitative Comparisons
In addition to the quantitative benchmarks, real-world users and experts provided valuable qualitative insights on how GPT-4o truly compares to models like Claude and ChatGPT across different use cases. We make qualitative notes from several Subreddit threads for this section.
Language and Tone
Multiple users noted that Claude has a more personable, friendly, empathetic and expressive communication style compared to the more robotic and neutral tone of ChatGPT.
"Claude is more personable, friendly, warm and empathetic. ChatGPT, by contrast, gets too robotic." (Source)
"(Claude) is much more natural in word usage as well as not repeating itself with the same phrase and using original verbiage." (Source)
However, some preferred ChatGPT's more neutral, matter-of-fact style: "If you like a more human tone, give Llama 3 a shot. Gemini's also not bad, but it has a lot of silly refusals as well. I prefer the more neutral, robotic, matter-of-fact tone of GPT most times." (Source)
Writing and Content Creation
For tasks like writing, content creation, and language processing, many found Claude to be superior to ChatGPT in areas like response length, eloquence, and avoiding telltale signs of AI-generated text.
"It isn't as limited in response length, so I can work much faster. It never back-talks me or gives me some variation of "I can't handle that request." It doesn't use insanely flowery language or stupid word choices that are a dead giveaway of AI-generated content." (Source)
"As a writer, I find Claude to be more eloquent..." (Source)
"Claude beats chatGPT for writing healthcare education materials, hands down." (Source)
"Claude Opus is far superior than ChatGPT 4 for copywriting. GPT has helps as an idea generator, but its writing is stiff. With Claude, I get a good rough draft of what I need from a few prompts, then I spend my time editing rather than writing." (Source)
Coding and Programming
A consistent trend was the strong preference for Claude, especially Claude 3 Opus, over ChatGPT and GPT-4 models for coding tasks. Users cited Claude's longer context window, better code reasoning, and superior handling of complex prompts as key advantages.
"Claude has consistently outperformed GPT-4 in the area of coding – generating templates, troubleshooting, and seeking explanations." (Source)
"I've been using Claude 3 primarily for coding, and it's been transformative compared to ChatGPT/GPT-4 for that. It's superior to ChatGPT/GPT-4 for one major reason - its context window." (Source)
"Claude opus gives very nice and thoughtful code, much much better then 4o...Claude has been better at esoteric C++ in my experience." (Source)
"Claude is the best at correctly following complex instructions in the prompt. It handles coding very well, even better if using at low temperature." (Source)
However, some users found GPT-4o to be superior for certain coding tasks:
"GPT4o is super fast, but I find it only really excels at pointing your camera at things, and asking somewhat involved questions about its contents...Reasoning can be more nuanced if prompted well." (Source)
"The new llmsys leaderboard rankings came out yesterday and GPT-4o took the first spot on the code category, so it seems to be doing something right for most people testing code on the arena." (Source)
Analysis and Context
Another key strength of Claude highlighted by users was its superior ability to handle analysis over long contexts and documents compared to GPT models.
"Claude now has a 200k token context window. (GPT-4 has max 128K)...For pure writing and responses, also for parsing large amounts of information and quickly learning a natural desired output, Claude 2 is far superior." (Source)
"Claude's context window makes it much more valuable than GPT4 if you want to feed Claude an entire codebase or a large chunk of it." (Source)
"Claude is significantly better at reasoning. WAY better. I think this is evident in stress tests involving causal probability, fictional writing with dozens of characters and their interactions with the environment, induction and deduction on real-life problems, and coding creative stuff." (Source)
Limitations and Drawbacks
While praising Claude's strengths, users also highlighted some key limitations and drawbacks compared to GPT models:
"INSANE refusal rate and false positives due to censorship. Seriously, this is embarrassing. GPT-4O, on the other hand, has no moral training, so it won't understand the difference between solving a riddle or saving a kitten. But will comply with like 98% requests." (Source)
"It can't surf the internet or produce images." (Source)
"Claude may be slightly more prone to sycophancy, though it's pretty common with LLMs in general. This is easily addressed with some promting I've found." (Source)
Some also noted the limitations of ChatGPT's chat interface for certain tasks:
"If you need a language model for analysis and iteration, you should be using the API. Claude's chat interface..." (Source)
"ChatGPT has limitations in response length, which slows down work...ChatGPT struggles with memory issues when coding, forgetting progress from prior prompts." (Source)
Overall, the qualitative feedback reveals key strengths of Claude like superior language quality, coding abilities, and context handling - while also highlighting areas where GPT models may still have an edge, such as avoiding censorship issues. Many took a hybrid approach, leveraging each model's strengths for different use cases.
Verdict
Based on the comprehensive quantitative benchmarks and real-world qualitative feedback, we can develop a nuanced perspective on how GPT-4o truly compares to models like Claude and Gemini across different core use cases.
General Task Performance
The benchmarks showed GPT-4o achieving elite scores above 85 on general language understanding tests like MMLU and multi-task evaluations. While Claude-3-Opus performed very strongly as well, GPT-4o demonstrated a slight edge for general language tasks.
However, qualitative feedback revealed GPT-4o can sometimes "go off the rails" and ignore important context, while Claude excelled at precisely following complex prompts and maintaining coherence. As one user put it:
"GPT-4o seems drunk and will ignore important details and just spew out some code. I'd correct it again, then again, then again, then we might have a solution. For Claude opus, I actually often trust it to rewrite my methods correctly and copy paste the new one with modifications, and it's always correct." (Source)
So while GPT-4o may have a slight quantitative edge, Claude could be the better choice for general tasks requiring high precision and strict adherence to prompts.
Coding
Both the benchmarks and qualitative feedback converged on Claude, especially Claude-3-Opus, being the superior model for coding and programming tasks. It outperformed GPT-4o on code generation benchmarks like HumanEval and was consistently praised by developers for its longer context window, better code reasoning, and ability to handle complex, technical prompts.
As one user summarized: "Claude opus gives very nice and thoughtful code, much much better then 4o...Claude has been better at esoteric C++ in my experience." (Source)
However, GPT-4o was noted as being potentially stronger for specific coding tasks like analyzing multimedia inputs and visual data. But for general coding use cases, Claude appears to be the model of choice.
Large Context / "Needle in Haystack" Problems
One of Claude's key advantages highlighted was its massive 200k token context window, compared to GPT-4's 128k limit. This allowed Claude to better handle analysis over long documents, large codebases, and what users referred to as "needle in a haystack" problems requiring reasoning over extensive context.
As one user noted: "Claude's context window makes it much more valuable than GPT4 if you want to feed Claude an entire codebase or a large chunk of it." (Source)
The benchmarks also showed Claude-3-Opus outperforming GPT-4o on tests like DROP that involved complex question answering over long contexts.
So for use cases like analyzing lengthy documents, legal contracts, or large data sources, Claude-3-Opus seems to be the superior choice thanks to its context abilities.
Writing (English)
When it came to general writing tasks like content creation, copywriting, and language processing, both the quantitative and qualitative data indicated Claude held an edge over GPT models like GPT-4o.
Users consistently praised Claude's more natural, eloquent, and human-like language outputs that avoided telltale signs of AI-generated text. As one user put it:
"Claude is much more natural in word usage as well as not repeating itself with the same phrase and using original verbiage." (Source)
The benchmarks also showed Claude outperforming GPT-4o on summarization tasks like MGSM that require strong language generation capabilities.
So for writing-focused use cases like creative writing, marketing copy, reports and more, Claude emerges as the superior model over GPT-4o based on both empirical results and real-world feedback.
While no model is a silver bullet, this multi-dimensional analysis provides a clear-eyed view into the strengths and limitations of GPT-4o versus Claude and other language models. By leveraging the right model for the right use case, you can maximize the value and effectiveness of these AI capabilities.
Conclusion: Strategic Model Selection for Maximum Value
The analysis we've covered allows you to cut through the noise and understand where GPT-4o truly excels versus alternatives like Claude for your unique use cases.
For general language tasks, GPT-4o demonstrated elite performance but may lack precision. For coding and programming, the data clearly favors Claude-3-Opus thanks to its longer context window and stronger code reasoning abilities.
When working with large documents or "needle in a haystack" problems, Claude's massive context window is a major advantage. And for writing tasks, Claude emerged as producing more natural, human-like outputs based on quantitative and qualitative evaluations.
By strategically selecting the right model per use case, you maximize effectiveness. A blended approach leveraging multiple models' strengths is optimal. Platforms like Wielded enable combining language models seamlessly.
And if you're spending more time rewriting and editing ChatGPT content than if you'd created it yourself, or can't seem to get rid of that telltale "AI voice", it may be time to level up your AI writing workflows. The AI Content Mastery course guides content teams in developing processes to create resonant, audience-centric content powered by AI - not generic, robotic outputs.
Don't get swayed by hype. Let benchmarks and real-world feedback guide you in unlocking these AI technologies' full potential for your needs.
Dominate ChatGPT and Google Search
Wielded helps B2B companies with SEO & GEO using programmatic SEO approach. Book a call to find out how we help you win.